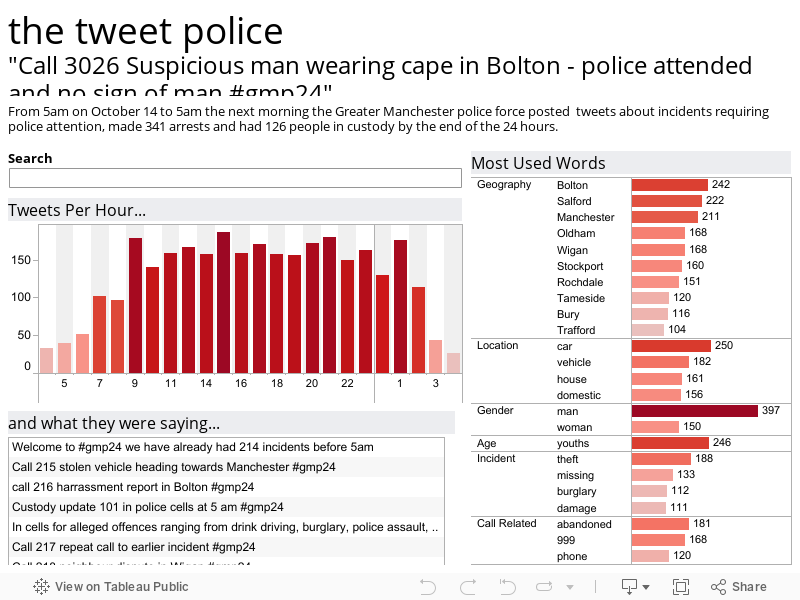
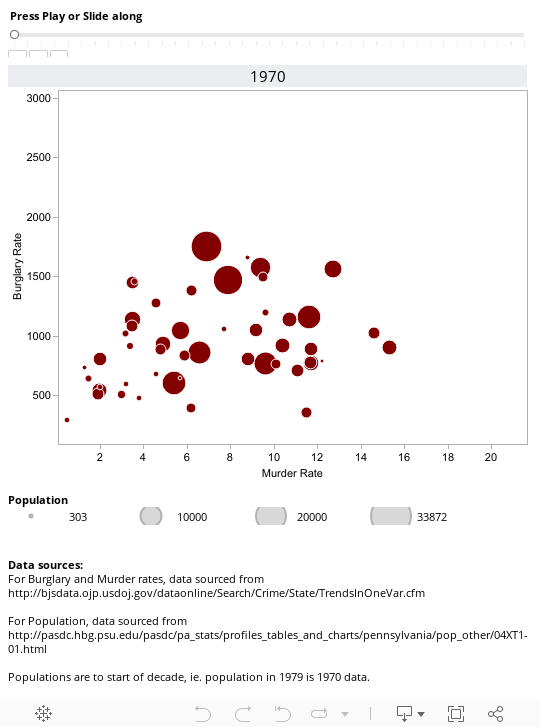
The visualisation allows you to see the rates of burglary and murder in all the states for any particular year. If you click on any one of the bubbles, it will show you the trail for that state since 1970 - so go to 2008 for a full trail and see how New York has changed over the time for instance.
Note that Tableau Public doesn't support the playback feature, so you'll need to download the workbook and open in reader to fully enjoy the animation. Try clicking on one of the circles in 1970 and then track how murder and burglary rates change over the 40 years by pressing the play button. California is an interesting one.
The Technical Bit
I sourced the data in the main via http://bjsdata.ojp.usdoj.gov/dataonline/Search/Crime/State/TrendsInOneVar.cfm and then transformed it into something more tableau friendly using the Tableau Add-In for Excel (this flattens the cross tabs).
To get hold of the population data, I used data here. As this is at ten year intervals, I used the floor function in excel to tie each individual year to the start of the decade it was in, so 1979 would be tied to the population in 1970.